


Оглавление

Шпаргалка по метрикам при обучении нейросетей
6 августа 2025
Время чтения: 20 минут
Автор статьи: Александр Медовник — CTO компании AppFox.
Меня зовут Александр, я CTO компании AppFox. Мы более 10 лет занимаемся заказной разработкой, а также имеем собственные продукты.
Нам часто приходится интегрировать нейросети в проекты, проводить prompt-инжиниринг и fine-tune. Качество и точность модели, при этом, являются ключевыми показателями. В этой статье мы разберем основные метрики нейросетей при обучении.
Но, прежде чем мы перейдем непосредственно к метрикам, необходимо рассмотреть классификацию ошибок.
Confusion Matrix
В машинном обучении, особенно в задачах классификации, важно не просто знать, сколько ошибок делает модель, но и различать качество этих ошибок. Для этого существует матрица ошибок (Confusion Matrix), которая делит предсказания модели на 4 категории. Давайте представим, что мы обучаем модель для будущего беспилотного автомобиля. Она должна определить наличие светофора на фото.
-
True Positive (TP).
Верный положительный ответ. Модель определила, что светофор на фото присутствует. И на самом деле он присутствует. -
False Positive (FP).
Ложный положительный ответ. Модель определила, что светофор есть, но на самом деле его нет. -
True Negative (TN).
Верный отрицательный ответ. Модель сказала, что светофора нет. И на самом деле его нет. -
False Negative (FN).
Ложный отрицательный ответ. Модель сказала, что светофора нет, но на самом деле он есть.
Такая классификация помогает:
- Считать метрики качества модели
- Понимать, где ошибается модель
- Выбирать оптимальный порог классификации
Ну, а теперь, собственно, о метриках.
Accuracy
Accuracy — это одна из ключевых метрик для оценки качества классификационных моделей. Она показывает долю правильных предсказаний модели относительно общего числа предсказаний.
Метрика Accuracy рассчитывается по следующей формуле:
Кол-во верных предсказаний / Общее кол-во предсказаний * 100%
Пример:
Модель говорит, что светофор присутствует или его нет. Из 100 тестовых фото:
- Верно предсказано: 90 случаев (85, где светофор есть + 5, где он отсутствует).
- Ошибки: 10 случаев.
Данная метрика подходит только в тех случаях, в которых классы сбалансированы. Т.е., у нас есть 50 фото со светофором и 50 без него. Кроме того, если важна только общая доля правильных ответов (без детализации по типам ошибок) и нам не важно, ошиблась модель, отвечая “да”, когда светофора не было или “нет”, когда он был.
Если же датасет не сбалансирован, например, у нас 85 фото со светофором и 15 без него, то данная метрика не имеет смысла. Модель, которая всегда предсказывает “да”, получит Accuracy в 85%, но результат будет мягко говоря неточный, так как неизвестно каким бы он был при противоположном соотношении. Данная метрика очень грубая, не различает False Positive (ложные срабатывания) от False Negative (пропуск цели) и поэтому, используется в редких случаях.
Precision (Точность/Прецизионность) в машинном обучении
Precision — это метрика, которая показывает, какая доля положительных предсказаний модели была верной. Она показывает, сколько раз была модель права из всех случаев, когда она сказала “да”.
Имеет следующую формулу:
Представим, что модель определила светофоры на 80 фото. Из них на 8 фото модель разглядела светофор там, где его нет (FP) ошиблась.
Метрика критически важна, когда ложные срабатывания (FP) дорого обходятся. Например, в спам-фильтре ошибочно поместить важное письмо в спам (FP) хуже, чем пропустить спам (FN). Еще пример — системы безопасности, в которых ложная тревога (FP) тратит ресурсы большие ресурсы.
И пример, когда Precision не подходит, — поиск тяжелых заболеваний по медицинским снимкам. Если заболевание редкое, то датасет будет несбалансированным. Больных, к примеру, 1%, а здоровых — 99. Если модель скажет "болен" только для 1 пациента из 1000, то Precision будет равен 100% (1 / (1 + 0) = 1). Модель сказала “болен” 1 раз и 1 раз она была права. Но при этом 9 больных умрут (10 больных из 1000 здоровых). Модель не считает их больными, а они таковыми являются (FN).
Recall (полнота) в машинном обучении
Recall (или чувствительность) — это метрика, которая показывает, какую долю реальных положительных случаев модель смогла правильно идентифицировать. Показывает, из всех реальных "да", сколько модель нашла.
Рассчитывается по формуле:
Например, набор данных состоит из 100 фото. Из них на 60 присутствует светофор, а на 40 его нет. Модель из 60 фото со светофорами отметила только 52 светофора (8 раз модель сказала “нет”, а на самом деле ответ был “да”) .
Рассчитаем метрику для этого случая:
Recall необходим, когда пропуск положительных случаев (FN) недопустим. Например, случаи в медицинской диагностике, при которых пропустить болезнь (FN) опаснее, чем создать ложную тревогу (FP) и назначить лечение по ошибке. При поиске мошенничества, когда невыявление реальной атаки (FN) принесет финансовые потери. В поисковых системах, когда пропуск релевантного документа (FN) может снизить качество выдачи.
В то же время, метрика не учитывает FP (модель пометила “светофор” на фото, а его там нет). Поэтому там, где она FP критично, данная метрика используется в паре с Precision и другими метриками.
F1-Score
Если важно учитывать и FP, и FN, используют F1-Score — среднее гармоническое Precision и Recall.
Формула:
или
Из определения следует, что данная метрика используется там, где важно учитывать как ложные срабатывания (FP), так и пропуски (FN) для задач с несбалансированными классами.
Пример расчета:
Данная модель одинаково хороша в точности и полноте. Данный вывод делается на основе того, что F1 стремится к 1.
Пример с дисбалансом в сторону Precision
Из примеров видно, что если одна из метрик ближе к 0, то и F1 стремится к нулю. Т.е., идеальная модель с точки зрения данной метрики – это модель, при которой F1 равна 1.
AUC-ROC (Area Under the ROC Curve) — площадь под ROC-кривой
AUC-ROC — это метрика, которая оценивает качество бинарной классификации независимо от порога классификации. Она показывает, насколько модель способна отличать положительные классы от отрицательных. Чем выше AUC-ROC (максимум 1), тем лучше модель.
Что такое AUC-ROC простыми словами?
AUC-ROC — это метрика, которая показывает, насколько хорошо модель отличает один класс от другого (фото со светофорами от фото без светофоров). Чем ближе AUC-ROC к 1, тем лучше модель. Если AUC-ROC = 0.5, модель работает как случайное угадывание.
Разберем, как это работает.
Сначала модель предсказывает вероятность. Например, для каждого фото модель выдает число от 0 до 1. При этом, 1 будет означать, что модель на 100% уверена в том, что на фото есть светофор, а 0 - что его нет.
Постепенно начинаем изменять порог уверенности. Сначала мы говорим, что если уверенность > 0.9, то светофор есть. Затем, что если > 0.8. И так далее до 0. На каждом шаге мы записываем результат.
Результат состоит из следующих категорий
True Positive Rate (TPR). Показывает, сколько фото со светофорами были правильно помечены. Вычисляется по формуле:
False Positive Rate (FPR). Отражает, сколько фото были помечены по ошибке.
Формула:
Итак, после того, как мы изменили порог уверенности и произвели замеры TPR и FPR, строим ROC-кривую, где по оси X находится FPR, а по оси Y - TPR.
Идеальная модель сразу даёт TPR=1 (все светофоры найдены) и FPR=0 (нет ложных срабатываний). Плохая же модель идёт по диагонали. Т.е., её предсказания больше похожи на рулетку.
Разберем примеры без лишних графиков и усложнений.
Представим, что всем фото со светофорами модель присвоила вероятность, близкую к 1 (например, 0.99, 0.95, 0.98). А фото без светофоров получили вероятность, близкую к 0 (например, 0.01, 0.02, 0.05).
Далее, сравниваем попарно.
- 0.99 > 0.01
- 0.99 > 0.02
- 0.99 > 0.05
- 0.95 > 0.01
- 0.95 > 0.02
- 0.95 > 0.05
- 0.98 > 0.01
- 0.98 > 0.02
- 0.98 > 0.05
Все сравнения верны. Т.е., в 100% случаев. Это означает, что AUC-ROC = 1.0.
Если же представить, что один светофор был определен по ошибке (например, 0.01, 0.02, 0.7), а один остался незамеченным (например, 0.99, 0.95, 0.6), то расклад уже будет другим.
- 0.99 > 0.01
- 0.99 > 0.02
- 0.99 > 0.7
- 0.95 > 0.01
- 0.95 > 0.02
- 0.95 > 0.7
- 0.6 > 0.01
- 0.6 > 0.02
- 0.6 < 0.7
Теперь AUC-ROC < 1.0, так как только 8 из 9 сравнений имеют положительный результат (88.89%).
В отличие от Accuracy, AUC-ROC устойчива к дисбалансу классов. Поэтому, ее рекомендуется использовать при несбалансированности данных. Также, метрика подходит там, где важны вероятности. Например, ранжирование заемщиков по риску.
В то же время, AUC-ROC не очень хорошо подходит для многоклассовой классификации.
BLEU (Bilingual Evaluation Understudy) — метрика оценки качества машинного перевода и генерации текста
BLEU — метрика, которая позволяет определить схожесть сгенерированного текста с эталонным человеческим. Качество модели оценивается тем лучше, чем BLEU ближе к 1 (или 100%).
Прежде чем понять данную метрику, необходимо разобрать, что такое N-граммы. Это последовательности из n подряд идущих элементов в тексте (слов, букв или других символов). Они используются для анализа, моделирования и генерации текста в задачах обработки естественного языка (NLP).
BLEU оценивает текст по двум критериям:
Точность n-грамм. Показывает, сколько n-грамм из предсказания совпали с эталонным текстом. Штраф за короткие предложения. Начисляется, если предсказание короче эталона. Оценка, при этом, снижается. Рассчитывается по формуле (пример на Python):
bleu = min(1, len_pred / len_ref) * exp(sum(w_n * log(p_n) for n, w_n in zip(range(1, N+1), weights)))
Где:
- len_pred — длина предсказанного текста,
- len_ref — длина эталонного текста.
- p_n — точность для n-грамм (доля совпавших n-грамм),
- weights — веса для n-грамм (обычно [0.25, 0.25, 0.25, 0.25]).
BLEU сравнивает текст как есть. Т.е., если модель выдает аналогичный текст, но слова заменены синонимами, то BLEU будет низким. Это подходит больше для переводчиков. И не подходит, например, для модели, которая позволяет сделать текст уникальным и пройти антиплагиат. Замена слов, “игра” слов, пересказ поэтическим языком будут расценены как несовпадение и ошибки.
IoU (Intersection over Union) — метрика для оценки качества детекции и сегментации объектов
IoU – это метрика, которая измеряет степень перекрытия между предсказанным объектом и реальным. Чем ближе IoU к 1, тем точнее модель локализует объект.
Рассчитывается по формуле: Intersection (пересечение) / Union (объединение)
Где:
- Intersection – площадь области, где предсказание и ground truth совпадают.
- Union — общая площадь, покрытая предсказанием и ground truth.
Пример расчета:
- Ground truth (реальный объект): Площадь = 100 px².
- Предсказание модели: Площадь = 80 px².
- Пересечение: 60 px².
- Объединение: 100 + 80 - 60 = 120 px².
- IoU = 60 / 120 = 0.5 (результат средний, требует улучшения модели)
IoU – это ключевая метрика для оценки точности локализации объектов в задачах компьютерного зрения. Она измеряет, насколько предсказанная область совпадает с реальной (ground truth).
Но, конечно, у данной метрики есть и минусы.
- Она не подходит в случаях, где должна учитываться форма объекта (например, IoU будет равен 0 для двух непересекающихся кругов, даже если они находятся близко).
- Она очень чувствительна к маленьким объектам. При этом, небольшие ошибки для маленьких объектов сильнее снижают IoU.
- Метрика не различает частичные перекрытия. Например, IoU, равное 0.5, может означать как 50% перекрытие, так и несколько мелких неточностей.
Perplexity (перплексия)
Метрика используется для оценки качества языковых моделей (LM) и генерации текста.
Чем меньше перплексия, тем лучше модель предсказывает текст.
Упрощенно можно представить так. Если перплексия равна 50, то модель сомневается, какое слово из 50 вариантов выбрать.
Чтобы не погружаться в математические дебри, рассмотрим формулу упрощенно на Python.
import numpy as np
probs = np.array([0.4, 0.6, 0.8, 0.2])
perplexity = np.exp(-np.mean(np.log(probs)))
print(round(perplexity, 2)) # Output: 3.81
Где:
probs - массив вероятностей, которые модель присвоила правильным словам в тексте (или другим целевым элементам).
np.log(probs): Логарифмируем вероятности (чтобы избежать численной нестабильности при умножении).
np.mean(): Усредняем логарифмы по всем элементам последовательности.
np.exp(): Возвращаемся из логарифмического пространства, получая итоговую перплексию.
Значение 3.81 означает, что модель в среднем "колеблется" между ~4 вариантами следующего слова.
Перплексия подходит при обучении моделей для генерации и автодополнении текста.
METEOR (Metric for Evaluation of Translation with Explicit ORdering)
METEOR — это метрика, предназначенная для оценки качества генерации текста, в первую очередь — машинного перевода. В отличие от BLEU, она не ограничивается точными совпадениями слов, а старается учитывать семантику: синонимы, морфологические формы, а также порядок слов.
Формула METEOR
Где:
F_mean — гармоническое среднее Precision и Recall.
Penalty — штраф за несовпадение порядка слов.
Например, если модель сгенерировала «Я люблю кофе», а эталон — «Кофе я люблю», BLEU выдаст низкую оценку, а METEOR поймёт, что это один и тот же смысл, просто порядок изменён, и присвоит оценку выше.
Эта метрика используется в задачах генерации текста, где важен смысл, а не дословное совпадение: машинный перевод, генерация описаний к изображениям, автоматическая суммаризация текста, диалоговые системы.
Главное достоинство METEOR — “понимание” контекста. Она не просто сравнивает текст по буквам, но пытается оценить его смысловую близость.
В отличие от BLEU, METEOR работает медленнее, так как требует морфологического анализа, работы с синонимами, а иногда и внешними словарями. Кроме того, для языков, где таких ресурсов мало (или они ограничены), метрика может работать не так точно.
MSE (Mean Squared Error)
MSE одна из самых популярных метрик при оценке регрессионных моделей. Она показывает, насколько сильно в среднем отличаются предсказанные значения от реальных, причём с усилением крупных ошибок за счёт возведения в квадрат.
Формула:
Где:
yᵢ — реальное значение
ŷᵢ — предсказанное значение
n— количество наблюдений
Пример:
Допустим, модель предсказывает [20, 30, 40], а реальные значения — [22, 28, 41], ошибки будут: [-2, 2, -1], квадраты ошибок: [4, 4, 1], MSE = (4 + 4 + 1)/3 = 3.0
Метрика применяется в задачах регрессии: от предсказания цены жилья и уровня загрязнения воздуха до моделирования спроса. Также используется как функция потерь при обучении нейросетей, если целью является точное числовое приближение.
Главный плюс MSE — простота и интерпретируемость. Чем меньше значение, тем ближе предсказания к реальности. А за счёт квадрата ошибок, она жёстко наказывает большие отклонения, что важно в чувствительных к точности задачах, например, в прогнозировании финансов.
Метрика плохо переносит выбросы. Одна крупная ошибка может сильно исказить общий результат. Поэтому, если в данных возможны аномалии, стоит рассмотреть альтернативы вроде MAE (Mean Absolute Error).

CER — Character Error Rate (посимвольная ошибка)
Character Error Rate — одна из ключевых метрик при оценке качества генерации текста, особенно в задачах, где важна посимвольная точность. Она измеряет долю символов, которые нужно изменить (удалить, заменить или вставить), чтобы предсказанный текст стал идентичным эталонному.
Формула:
Где:
S — количество замен символов
D — удалений
I — вставок
N — общее число символов в эталонном (референсном) тексте.
Допустим, эталонная строка — «машина», а модель выдала «масина». В этом случае: замена: “и” → “с”.
Всего одна ошибка на 6 символов: CER = 1 / 6 ≈ 0.16
CER активно применяется в системах распознавания речи (ASR), OCR (распознавание текста с изображений), чат-ботах и системах автодополнения текста, где важна точность на уровне символов. Например, при распознавании паспортных данных с фото, даже одна буква может полностью изменить смысл, и в таких случаях посимвольная метрика предпочтительнее, чем смысловая.
Главное достоинство CER — высокая точность и строгость. Она не прощает ошибок и позволяет объективно судить о качестве модели, если важен каждый символ. В задачах, где недопустимы даже малейшие искажения (например, распознавание медицинских терминов, имён собственных, кодов или артикулов), CER даёт наиболее честную картину.
Но CER никак не учитывает смысл текста. Если два предложения означают одно и то же, но написаны разными словами — метрика всё равно поставит низкий балл. Она игнорирует синонимы, грамматические формы, перестановку слов. Поэтому CER не годится для оценки моделей генерации, где важна семантика, а не дословное совпадение.
Dice Score — перекрытие предсказания и реальности
Dice Score (также известный как Dice Coefficient) — метрика, широко применяемая в задачах сегментации изображений, особенно в медицине, компьютерном зрении и автопилотах. Она показывает, насколько сильно пересекаются два множества — предсказанная область и реальная (ground truth). Чем больше перекрытие, тем выше Dice.
Формула:
Где:
A — множество пикселей, предсказанных моделью как объект
B — множество пикселей, размеченных вручную (ground truth)
|A ∩ B| — количество пикселей, правильно угаданных моделью.
Пусть модель предсказала объект в 60 пикселях, ground truth — тоже 60 пикселей, и пересечение составляет 50 пикселей.
Метрика крайне популярна в медицинских задачах: сегментация опухолей на МРТ/КТ, размечивание анатомических структур, подсчет клеток. Также используется в автопилотах (выделение полос, объектов), в анализе спутниковых снимков, при работе с биометрическими данными (например, сегментация радужки глаза).
Dice Score прекрасно подходит для оценки маленьких объектов, где даже незначительное расхождение может серьёзно повлиять на результат. Она очень чувствительна к совпадению, поэтому хороша для оценки точности локализации. Учитывая размер пересечения, Dice позволяет понять, насколько модель действительно "попала" в цель, а не просто приблизилась.
Из недостатков: метрика чувствительна к шуму: даже небольшие расхождения на краях объекта могут сильно снизить Dice. Кроме того, она не показывает, где именно модель ошиблась — можно получить одинаковый Dice при разных типах ошибок. Также метрика плохо себя показывает, если объекты очень малы — один лишний или пропущенный пиксель влияет непропорционально сильно.
CIDEr (Consensus-based Image Description Evaluation)
CIDEr — специализированная метрика для оценки текстов, сгенерированных по изображению. Её основная задача в определении, насколько хорошо сгенерированное описание совпадает с человеческими эталонами, при этом делая акцент на важные слова. Используется также в обучении и тестировании мультимодальных моделей (например, CLIP) и в области компьютерного зрения и NLP.
В отличие от BLEU и METEOR, CIDEr использует TF-IDF (веса частоты и уникальности слов) и n-граммы для точной оценки содержательного соответствия. Особенно полезна, когда к одному изображению есть несколько эталонных описаний.
Формула (в упрощённом виде):
CIDEr вычисляется как косинусное сходство между TF-IDF-векторами n-грамм предсказания и эталонов, усреднённое по n (обычно от 1 до 4):
Где:
CIDEr — итоговая оценка схожести предсказания с эталонами по метрике CIDEr.
N — количество порядков n-грамм, по которым происходит сравнение (обычно N=4N = 4N=4, то есть от 1-грамм до 4-грамм включительно).
∑n=1,N р2 — суммирование по всем порядкам n-грамм (1-граммы, 2-граммы, 3-граммы, 4-граммы).
TFIDFpred,n — TF-IDF вектор n-грамм, полученных из предсказания (candidate caption).
TFIDFrefs,n — TF-IDF векторы n-грамм для всех эталонных подписей (reference captions).
mean(TFIDFrefs,n) — средний TF-IDF вектор по всем эталонам для данного порядка n-грамм.
cos(⋅,⋅) — косинусное сходство между векторами.
Если модель описывает изображение как «собака бежит по траве», а эталон «пёс мчится по зелёному полю», то CIDEr «поймёт», что это близкие по смыслу описания, потому что «собака» ≈ «пёс», «по траве» ≈ «по полю», и все слова содержательны и редки.
Метрика делает акцент на важные (редкие) слова, что позволяет лучше оценивать содержательность текста. Она снижает вес частых слов («это», «на», «и») и повышает значимость уникальных признаков изображения.
CIDEr особенно эффективна в задачах, где есть несколько корректных ответов — то есть когда идеального единственного эталона не существует.
Для работы требуется множество эталонных описаний на каждое изображение, иначе метрика может быть слишком чувствительной к стилистическим расхождениям. Кроме того, расчёт CIDEr требует больше ресурсов, чем BLEU или METEOR.
PSNR (Peak Signal-to-Noise Ratio)
PSNR (пиковое отношение сигнала к шуму) — это метрика, которая измеряет качество сжатия или восстановления изображений (и видео), сравнивая оригинал с предсказанным изображением. Чем выше PSNR, тем меньше искажений и ближе восстановленное изображение к оригиналу.
Метрику чаще всего применяют в задачах видеокодирования (например, сравнение эффективности кодеков), сжатия изображений, восстановления изображений в суперрезолюшене или после применения автокодировщиков. Она удобна тем, что легко интерпретируется и не требует предварительного обучения или привлечения внешних оценщиков — одна формула, одно число, быстрая оценка.
Формула:
Где:
MAX — максимальное возможное значение пикселя (например, 255 для 8-битных изображений)
MSE — среднеквадратичное отклонение между пикселями оригинала и предсказания
Чем меньше MSE (ошибка), тем выше PSNR.
Даже небольшие отличия дают высокий PSNR (около 40 дБ — это считается хорошим качеством).
У метрики есть существенные ограничения. Основной плюс — это простота, скорость и понятная интерпретация. Она хорошо показывает грубые искажения, когда разница между изображениями очевидна.
Однако большой минус в том, что PSNR плохо коррелирует с восприятием человеком. Два изображения с одинаковым PSNR могут визуально сильно различаться по качеству. Поэтому в задачах, где важно именно визуальное соответствие, PSNR используют скорее как базовый ориентир, а для финальной оценки обращаются к более «человекоориентированным» метрикам — SSIM, LPIPS, FID.
NDCG (Normalized Discounted Cumulative Gain)
Это метрика, которая оценивает качество ранжирования, особенно когда релевантность результатов не бинарна (т.е. не просто "да" или "нет", а, например, от 0 до 3 или от 0 до 5). Эта метрика учитывает как порядок элементов в выдаче, так и степень их полезности для пользователя.
Формально, метрика строится на основе DCG (Discounted Cumulative Gain) — кумулятивного прироста полезности от элементов, скорректированного с учётом их позиции:
Где:
rel_i — релевантность элемента на позиции iii,
p — число учитываемых позиций.
Чем выше позиция (то есть чем ближе к началу списка), тем больший вклад она вносит. Поэтому значения релевантности элементов на первых местах весомее.
Чтобы результат можно было сравнивать между собой, DCG нормализуется на IDCG — идеальный DCG, который можно было бы получить, если бы результаты были отсортированы в оптимальном порядке (сначала самые релевантные):
Таким образом, итоговое значение NDCG всегда от 0 до 1. Чем ближе к 1 — тем лучше качество ранжирования.
Метрика NDCG активно применяется в системах рекомендаций (например, подбор видео или товаров), поисковых движках (Google, Яндекс), ранжировании новостей, в задачах, где важно показывать самые полезные элементы первыми. Особенно полезна, если релевантность может быть выражена градуированно (например, пользователь поставил 1 звезду, 3 звезды или 5 звёзд).
Из преимуществ — учитывается и порядок элементов, и их важность, а также возможна гибкая настройка глубины расчёта (например, NDCG@10 — только по первым 10 позициям). Это делает метрику более чувствительной к качеству ранжирования, чем просто Precision или Recall.
Среди недостатков — сложнее интерпретировать результат на интуитивном уровне, особенно при дробных значениях; также может быть чувствительна к шуму в данных, особенно при большом разбросе в релевантности.
Такой подход показывает, насколько хорошо система ранжировала результаты по сравнению с идеальным сценарием. Это важный инструмент в задачах, где пользователю нужно сразу выдать "лучшее из возможного".
Средние метрики в мультиклассовой классификации
Когда модель работает не с двумя, а с несколькими классами (мультиклассовая классификация), возникает вопрос: как агрегировать значения метрик (precision, recall, F1 и т.п.), рассчитанных для каждого класса? Для этого используют стратегии усреднения — это и есть "средние метрики". Основных подходов три: macro, micro и weighted averaging.
Macro averaging
Для каждой метрики (например, precision) считается её значение по каждому классу независимо, а затем берется среднее арифметическое.
Формула:
Где:
P₁...Pₙ — значения precision по каждому из n классов.
Аналогично считаются macro-recall, macro-F1.
Этот подход не учитывает дисбаланс классов, все они равны по значимости. Может быть полезен, если все классы важны одинаково, независимо от их частоты.
Micro averaging
Здесь сначала суммируются все TP, FP и FN по всем классам, а затем по этим агрегированным значениям считается метрика.
Формулы:
Такой подход учитывает размер классов, фактически обращаясь с задачей как с бинарной на уровне отдельных элементов. Особенно полезен при сильном дисбалансе классов и когда важно глобальное качество классификации.
Weighted averaging
Значения метрик по каждому классу усредняются с учетом их веса — доли объектов этого класса во всей выборке.
Формула:
Где:
Pᵢ — precision для класса i,
wᵢ — доля объектов класса i.
Аналогично считаются weighted-recall и weighted-F1.
Этот подход сохраняет чувствительность к дисбалансу классов, но при этом дает более сбалансированную картину, чем micro, так как различает классы.
Особенности применения
Macro averaging — хорош для оценки по "слабым" классам, поскольку не дает доминировать "большим" классам. Micro averaging — эффективен, когда важна общая точность классификации. Weighted averaging — предпочтителен, если классы сильно неравновесны, но важно сохранить представление о каждом классе.
Уверенность модели (model confidence)
Уверенность модели — это числовое выражение того, насколько уверенно модель делает свое предсказание. Обычно она представляется в виде вероятностей, выдаваемых на выходе softmax (в классификации) или сигмоидной функции (в бинарной классификации или multilabel-задачах).
Оценка уверенности модели особенно важна:
- в задачах медицины, автономного вождения, финансов, информационного поиска — там, где ошибка может дорого стоить;
- в активном обучении для выбора наиболее неуверенных примеров;
- в калибровке моделей и постобработке предсказаний;
- в системах с human-in-the-loop, чтобы человек проверял предсказания, в которых модель не уверена.
Как измеряется уверенность
Типичный способ — взять максимальное значение вероятностей, выдаваемых моделью. Для классификации:
Где:
p1, p2,…рk — вероятности, которые присвоила модель каждому из k классов,
k — общее число классов.
Функция max выбирает наибольшее значение среди них, то есть вероятность того класса, который модель считает наиболее вероятным.
Пример:
Пусть softmax на выходе дал: [0.10, 0.05, 0.02, 0.78, 0.05]
Значит, модель предсказывает класс №4 с уверенностью 0.78.
Как интерпретировать:
Высокая уверенность + правильный ответ — модель работает хорошо.
Высокая уверенность + ошибка — опасный случай, возможна переуверенность.
Низкая уверенность + ошибка — допустимо, модель "понимает", что не уверена.
Низкая уверенность + правильный ответ — может свидетельствовать о неустойчивости модели.
Метрики, которые используют уверенность
Brier Score — оценивает точность предсказанных вероятностей.
Где:
pi — предсказанная вероятность,
yi ∈ {0,1} — истинная метка.
Log Loss (Cross-Entropy) — штрафует за уверенные, но неправильные предсказания:
Плюсы
- Позволяет не только предсказывать, но и понимать, насколько можно доверять модели.
- Необходима в риск-ориентированных приложениях.
- Используется при построении доверительных интервалов и калибровке.
Минусы
- Уверенность ≠ точность. Модель может быть уверенной, но ошибаться.
- Модели часто переуверены (особенно нейросети без калибровки).
- Требуется дополнительный анализ или калибровка, чтобы использовать уверенность корректно.
Калибровка модели (в связке с уверенностью)
Модель может предсказывать 0.95, но при этом быть права только в 70% таких случаев. Это значит — модель
не откалибрована.
Типичные методы калибровки:
- Platt Scaling (для бинарной классификации)
- Temperature Scaling (для softmax)
- Isotonic Regression (непараметрический способ)

Измерение галлюцинаций
Галлюцинации в моделях, особенно языковых (LLM), — это ситуации, когда модель выдаёт уверенный, но ложный или выдуманный ответ. Это может быть придуманный факт, несоответствие источникам, или логическая ошибка. В генеративных задачах галлюцинации — одна из самых серьёзных проблем.
Измерять галлюцинации сложно: у модели нет встроенного понимания правды, и она не знает, когда врёт. Поэтому оценки галлюцинаций часто делаются постфактум, с привлечением людей (ручная валидация), мета-моделей (детекторы галлюцинаций) или сравнения с базами знаний или источниками.
Пока нет универсального определения галлюцинации, всё зависит от задачи и контекста. Автоматические методы оценки ещё далеки от надёжности, поэтому требуется ручная разметка или наличие "истины", с которой можно сравнивать.
Среди автоматических можно выделить:
FactCC — модель-классификатор, обученная различать фактологически верные и ложные высказывания. Применима для задач суммаризации.
DAE Score (Dependency Arc Entailment) — основан на сопоставлении смысловой близости между сгенерированным и исходным текстом через синтаксические связи. Часто используется в задачах абстрактной суммаризации.
QAGS (Question Answering and Generation Score) — применим в задачах суммаризации и генерации. Оценивает фактологическую точность через промежуточные шаги: генерация вопросов по оригинальному тексту и получение ответов на них из сгенерированного. Чем больше совпадений, тем ниже уровень галлюцинаций.
GPT-based оценка — использование крупной модели (чаще всего GPT) для анализа фактической достоверности текста. Модель получает инструкцию: "Оцени, содержит ли данный текст утверждения, не подтверждаемые оригиналом", — и возвращает бинарный или градуированный вывод.
Одни из наиболее известных протоколов ручной аннотации HALO, HELP и MAF предлагают формализованные подходы, которые позволяют оценивать не просто факт искажения, но и его характер, контекст, уровень серьёзности.
HALO (Hallucination Annotation with Logical Outline) — применяется в первую очередь в задачах open-domain диалогов.
Аннотация проводится вручную по заранее заданной схеме: оценивается, насколько генерация модели соответствует исходным фактам, и классифицируется тип галлюцинации.
Например, если пользователь спрашивает у модели: «Кто написал Преступление и наказание?», и та отвечает «Лев Толстой», HALO позволит оценить это как полную фактическую ошибку — придуманную галлюцинацию.
Если же модель скажет, что роман написал Достоевский, но в 1885 году (вместо 1866), это будет искажённый факт.
HALO также учитывает логические ошибки: если вывод модели формально вытекает из данных, но логика нарушена (например, делает обобщения без основания), аннотаторы фиксируют это как логическую галлюцинацию.
Этот протокол полезен для оценки моделей, предназначенных для общения с пользователями, где важно, чтобы модель не только звучала убедительно, но и говорила по делу.
HELP (Hallucination Evaluation with Language Professionals) — используется в медицинских задачах, где ошибки модели могут стоить дорого. Здесь аннотирование проводят врачи или медицинские редакторы.
Они вручную оценивают тексты, сгенерированные моделью (например, ответы на клинические вопросы), и помечают фрагменты, содержащие недостоверную информацию.
Особенность HELP в том, что здесь учитываются не только явные фактические ошибки, но и потенциально опасные домыслы: например, если модель «рекомендует» метод лечения, эффективность которого не доказана, либо путает дозировки препаратов. Такая разметка требует глубоких знаний предметной области и чаще всего применяется в исследовательских работах или при тестировании медицинских чат-ботов.
MAF (Meaning Addition, Alteration, Fabrication) — это ещё один ручной протокол, ориентированный на разложение галлюцинации по типу и степени искажения. Он используется, например, при оценке саммари моделей (рефератов, пересказов и т.п.).
В рамках MAF аннотаторы определяют, добавила ли модель информацию, которой не было в исходном тексте (fabrication), изменила ли смысл (alteration) или добавила дополнительный смысл, который сложно проверить (addition).
Например, если модель суммирует статью о климате и «добавляет» утверждение о прямой связи между CO₂ и ураганами (чего в исходной статье нет), это будет fabrication.
Такой подход удобен в задачах суммаризации, реферирования, генерации новостей, особенно если важно избежать недостоверных обобщений.
Эти ручные метрики помогают строить датасеты для последующей автоматической оценки, калибровки моделей и обучения на обратной связи. Несмотря на их трудоёмкость, именно они задают стандарт, по которому можно сравнивать работу разных моделей на чувствительных или требующих фактической строгости задачах.
Как улучшить метрики
-
Несмотря на разнообразие метрик, применяемых к генеративным моделям, в реальности ни одна из них не даёт полного и универсального представления о качестве. Особенно это касается задач, связанных с безопасностью, точностью и правдоподобием. Чтобы сделать оценку более надёжной и информативной, необходимо улучшать как сами метрики, так и подход к их использованию.
-
Во-первых, метрики должны быть тесно связаны с задачей. Для диалоговых моделей важно измерять не только синтаксическое качество (например, BLEU), но и фактологическую достоверность, релевантность контексту и логическую связность. А в медицинских задачах, где критична точность, ручная разметка (например, с использованием протоколов HELP) пока остаётся золотым стандартом. Улучшение возможно за счёт адаптации метрик к конкретной предметной области и усиления контроля качества аннотаций.
-
Во-вторых, нужно учитывать, что модели могут быть уверены в неправильных ответах. Калибровка и анализ уверенности (confidence estimation) должны использоваться не как самостоятельные показатели, а как контекстные сигналы — особенно в системах, где пользователь полагается на точность генерации. Метрики, измеряющие калиброванность, такие как ECE (Expected Calibration Error), в этом случае могут дополнять общую картину.
-
В задачах детекции галлюцинаций важно сочетать автоматические и ручные методы. Пока ручные метки (HALO, HELP, MAF) остаются более надёжными, особенно при тонкой экспертной оценке (например, в медицине или юридическом секторе), автоматические методы развиваются в сторону использования более сильных моделей-критиков или цепочек проверок (chain-of-thought verification, self-consistency и др.). Усовершенствование возможно за счёт объединения нескольких подходов: автоматическая фильтрация и приоритизация спорных случаев, последующая экспертная валидация, обучение на таких примерах.
-
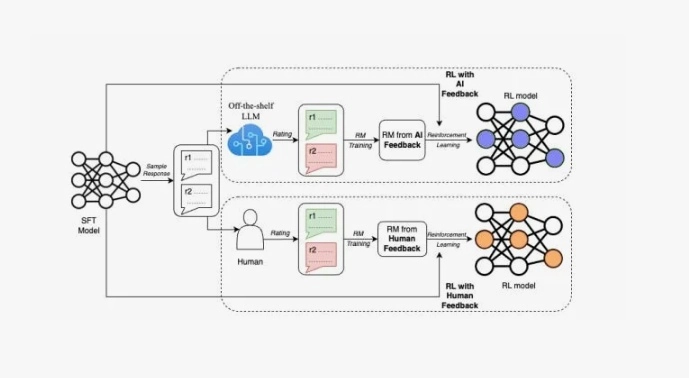
Наконец, улучшать стоит не только метрики, но и процесс их применения. Например, важно измерять вариативность ответов модели и стабильность метрик между запусками. Это помогает отличить реальные улучшения от случайных флуктуаций. Также всё чаще применяют комплексные системы оценки: автоматическая преференциальная модель, подкреплённая пользовательским фидбэком, с итоговым агрегированием результатов — именно такой подход сейчас используется в крупных LLM-платформах.
-
В идеале, метрики должны быть не просто числами, а системой сигналов, которая помогает понять: что именно пошло не так, как это исправить и насколько генерация безопасна и полезна. Пока же лучшая практика — это комбинация разных оценок, ориентированных на задачу, а также участие человека в критически важных случаях.
Метрики — это язык, на котором модель «разговаривает» с исследователем. Понимание их возможностей и ограничений позволяет не только точнее измерять качество, но и осознанно улучшать поведение ИИ-систем под конкретные задачи.

